Introducción al Deep Learning

El Deep Learning es sin duda el área de investigación más popular dentro del campo de la Inteligencia Artificial. La mayoría de las nuevas investigaciones que se realizan, trabajan con modelos basados en las técnicas de Deep Learning; ya que las mismas han logrado resultados sorprendes en campos como procesamiento del lenguaje natural y Visión por computadora. Pero... ¿qué es este misterioso concepto que ha ganado tanta popularidad? y... ¿cómo se relaciona con el campo de la Inteligencia Artificial y el Machine Learning?.
Inteligencia artificial, Machine learning y Deep learning
En general se suelen utilizar los términos de Inteligencia Artificial, Machine Learning y Deep Learning en forma intercambiada. Sin embargo, éstos términos no son los mismo y abarcan distintas cosas.
Inteligencia Artificial
El término Inteligencia Artificial es el más general y engloba a los campos de Machine Learning y Deep Learning junto con otras técnicas como los algoritmos de búsqueda, el razonamiento simbólico, el razonamiento lógico y la estadística. Nació en los años 1950s, cuando un grupo de pioneros de la computación comenzaron a preguntarse si se podía hacer que las computadoras pensaran. Una definición concisa de la Inteligencia Artificial sería: el esfuerzo para automatizar las tareas intelectuales que normalmente realizan los seres humanos.
Machine Learning
El Machine Learning o Aprendizaje automático se refiere a un amplio conjunto de técnicas informáticas que nos permiten dar a las computadoras la capacidad de aprender sin ser explícitamente programadas. Hay muchos tipos diferentes de algoritmos de Aprendizaje automático, entre los que se encuentran el aprendizaje por refuerzo, los algoritmos genéticos, el aprendizaje basado en reglas de asociación, los algoritmos de agrupamiento, los árboles de decisión, las máquinas de vectores de soporte y las redes neuronales. Actualmente, los algoritmos más populares dentro de este campo son los de Deep Learning.
Deep Learning
El Deep Learning o aprendizaje profundo es un subcampo dentro del Machine Learning, el cuál utiliza distintas estructuras de redes neuronales para lograr el aprendizaje de sucesivas capas de representaciones cada vez más significativas de los datos. El profundo o deep en Deep Learning hace referencia a la cantidad de capas de representaciones que se utilizan en el modelo; en general se suelen utilizar decenas o incluso cientos de capas de representación. las cuales aprenden automáticamente a medida que el modelo es entrenado con los datos.

¿Qué es el Deep Learning?
Antes de poder entender que es el Deep Learning, debemos en primer lugar conocer dos conceptos fundamentales: las redes neuronales artificiales y la Propagación hacia atrás.
Redes Neuronales
Las redes neuronales son un modelo computacional basado en un gran conjunto de unidades neuronales simples (neuronas artificiales), de forma aproximadamente análoga al comportamiento observado en los axones de las neuronas en los cerebros biológicos.
Cada una de estas neuronas simples, va a tener una forma similar al siguiente diagrama:
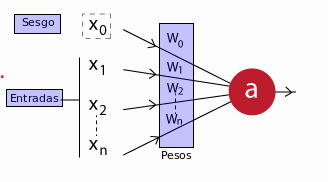
En donde sus componentes son:
-
$x_1, x_2, \dots, x_n$: Los datos de entrada en la neurona, los cuales también puede ser que sean producto de la salida de otra neurona de la red.
-
$x_0$: La unidad de sesgo; un valor constante que se le suma a la entrada de la función de activación de la neurona. Generalmente tiene el valor 1. Este valor va a permitir cambiar la función de activación hacia la derecha o izquierda, otorgándole más flexibilidad para aprender a la neurona.
-
$w_0, w_1, w_2, \dots, w_n$: Los pesos relativos de cada entrada. Tener en cuenta que incluso la unidad de sesgo tiene un peso.
-
a: La salida de la neurona. Que va a ser calculada de la siguiente forma:
$$a = f\left(\sum_{i=0}^n w_i \cdot x_i \right)$$
Aquí $f$ es la función de activación de la neurona. Esta función es la que le otorga tanta flexibilidad a las redes neuronales y le permite estimar complejas relaciones no lineales en los datos. Puede ser tanto una función lineal, una función logística, hiperbólica, etc.
Cada unidad neuronal está conectada con muchas otras y los enlaces entre ellas pueden incrementar o inhibir el estado de activación de las neuronas adyacentes. Estos sistemas aprenden y se forman a sí mismos, en lugar de ser programados de forma explícita, y sobresalen en áreas donde la detección de soluciones o características es difícil de expresar con la programación convencional.

Propagación hacia atrás
La propagación hacia atrás o backpropagation es un algoritmo que funciona mediante la determinación de la pérdida (o error) en la salida y luego propagándolo de nuevo hacia atrás en la red. De esta forma los pesos se van actualizando para minimizar el error resultante de cada neurona. Este algoritmo es lo que les permite a las redes neuronales aprender.

¿Cómo funciona el Deep Learning?
En general, cualquier técnica de Machine Learning trata de realizar la asignación de entradas (por ejemplo, imágenes) a salidas objetivo (Por ejemplo, la etiqueta "gato"), mediante la observación de un gran número de ejemplos de entradas y salidas. El Deep Learning realiza este mapeo de entrada-a-objetivo por medio de una red neuronal artificial que está compuesta de un número grande de capas dispuestas en forma de jerarquía. La red aprende algo simple en la capa inicial de la jerarquía y luego envía esta información a la siguiente capa. La siguiente capa toma esta información simple, lo combina en algo que es un poco más complejo, y lo pasa a la tercer capa. Este proceso continúa de forma tal que cada capa de la jerarquía construye algo más complejo de la entrada que recibió de la capa anterior. De esta forma, la red irá aprendiendo por medio de la exposición a los datos de ejemplo.
La especificación de lo que cada capa hace a la entrada que recibe es almacenada en los pesos de la capa, que en esencia, no son más que números. Utilizando terminología más técnica podemos decir que la transformación de datos que se produce en la capa es parametrizada por sus pesos. Para que la red aprenda debemos encontrar los pesos de todas las capas de forma tal que la red realice un mapeo perfecto entre los ejemplos de entrada con sus respectivas salidas objetivo. Pero el problema reside en que una red de Deep Learning puede tener millones de parámetros, por lo que encontrar el valor correcto de todos ellos puede ser una tarea realmente muy difícil, especialmente si la modificación del valor de uno de ellos afecta a todos los demás.

Para poder controlar algo, en primer lugar debemos poder observarlo. En este sentido, para controlar la salida de la red neuronal, deberíamos poder medir cuan lejos esta la salida que obtuvimos de la que se esperaba obtener. Este es el trabajo de la función de pérdida de la red. Esta función toma las predicciones que realiza el modelo y los valores objetivos (lo que realmente esperamos que la red produzca), y calcula cuán lejos estamos de ese valor, de esta manera, podemos capturar que tan bien esta funcionando el modelo para el ejemplo especificado. El truco fundamental del Deep Learning es utilizar el valor que nos devuelve esta función de pérdida para retroalimentar la red y ajustar los pesos en la dirección que vayan reduciendo la pérdida del modelo para cada ejemplo. Este ajuste, es el trabajo del optimizador, el cuál implementa la propagación hacia atrás.

Resumiendo, el funcionamiento sería el siguiente: inicialmente, los pesos de cada capa son asignados en forma aleatoria, por lo que la red simplemente implementa una serie de transformaciones aleatorias. En este primer paso, obviamente la salida del modelo dista bastante del ideal que deseamos obtener, por lo que el valor de la función de pérdida va a ser bastante alto. Pero a medida que la red va procesando nuevos casos, los pesos se van ajustando de forma tal de ir reduciendo cada vez más el valor de la función de pérdida. Este proceso es el que se conoce como entrenamiento de la red, el cual repetido una suficiente cantidad de veces, generalmente 10 iteraciones de miles de ejemplos, logra que los pesos se ajusten a los que minimizan la función de pérdida. Una red que ha minimizado la pérdida es la que logra los resultados que mejor se ajustan a las salidas objetivo, es decir, que el modelo se encuentra entrenado.
Arquitecturas de Deep Learning
La estructura de datos fundamental de una red neuronal está vagamente inspirada en el cerebro humano. Cada una de nuestras células cerebrales (neuronas) está conectada a muchas otras neuronas por sinapsis. A medida que experimentamos e interactuamos con el mundo, nuestro cerebro crea nuevas conexiones, refuerza algunas conexiones y debilita a los demás. De esta forma, en nuestro cerebro se desarrollan ciertas regiones que se especializan en el procesamiento de determinadas entradas. Así vamos a tener un área especializada en la visión, otra que se especializa en la audición, otra para el lenguaje, etc. De forma similar, dependiendo del tipo de entradas con las que trabajemos, van a existir distintas arquitecturas de redes neuronales que mejor se adaptan para procesar esa información. Algunas de las arquitecturas más populares son:
Redes neuronales prealimentadas
Las Redes neuronales prealimentadas fueron las primeras que se desarrollaron y son el modelo más sencillo. En estas redes la información se mueve en una sola dirección: hacia adelante. Los principales exponentes de este tipo de arquitectura son el perceptrón y el perceptrón multicapa. Se suelen utilizar en problemas de clasificación simples.

Redes neuronales convolucionales
Las redes neuronales convolucionales son muy similares a las redes neuronales ordinarias como el perceptron multicapa; se componen de neuronas que tienen pesos y sesgos que pueden aprender. Cada neurona recibe algunas entradas, realiza un producto escalar y luego aplica una función de activación. Al igual que en el perceptron multicapa también vamos a tener una función de pérdida o costo sobre la última capa, la cual estará totalmente conectada. Lo que diferencia a las redes neuronales convolucionales es que suponen explícitamente que las entradas son imágenes, lo que nos permite codificar ciertas propiedades en la arquitectura; permitiendo ganar en eficiencia y reducir la cantidad de parámetros en la red.
En general, las redes neuronales convolucionales van a estar construidas con una estructura que contendrá 3 tipos distintos de capas:
- Una capa convolucional, que es la que le da le nombre a la red.
- Una capa de reducción o de pooling, la cual va a reducir la cantidad de parámetros al quedarse con las características más comunes.
- Una capa clasificadora totalmente conectada, la cual nos va dar el resultado final de la red.
Algunas implementaciones específicas que podemos encontrar sobre este tipo de redes son: inception v3, ResNet, VGG16 y xception, entre otras. Todas ellas han logrado excelentes resultados.

Redes neuronales recurrentes
Los seres humanos no comenzamos nuestro pensamiento desde cero cada segundo, sino que los mismos tienen una persistencia. Las Redes neuronales prealimentadas tradicionales no cuentan con esta persistencia, y esto parece una deficiencia importante. Las Redes neuronales recurrentes abordan este problema. Son redes con bucles de retroalimentación, que permiten que la información persista.
Una Red neural recurrente puede ser pensada como una red con múltiples copias de ella misma, en las que cada una de ellas pasa un mensaje a su sucesor. Esta naturaleza en forma de cadena revela que las Redes neurales recurrentes están íntimamente relacionadas con las secuencias y listas; por lo que son ideales para trabajar con este tipo de datos. En los últimos años, ha habido un éxito increíble aplicando Redes neurales recurrentes a una variedad de problemas como: reconocimiento de voz, modelado de lenguaje, traducción, subtítulos de imágenes y la lista continúa.
Las redes de memoria de largo plazo a corto plazo - generalmente llamadas LSTMs - son un tipo especial de Redes neurales recurrentes, capaces de aprender dependencias a largo plazo. Ellas también tienen una estructura como cadena, pero el módulo de repetición tiene una estructura diferente. En lugar de tener una sola capa de red neuronal, tiene cuatro, que interactúan de una manera especial permitiendo tener una memoria a más largo plazo.

Para más información sobre diferentes arquitecturas de redes neuronales pueden visitar el siguiente artículo de wikipedia.
Logros del Deep Learning
En los últimos años el Deep Learning ha producido toda una revolución en el campo del Machine Learning, con resultados notables en todos los problemas de percepción, como ver y escuchar, problemas que implican habilidades que parecen muy naturales e intuitivas para los seres humanos, pero que desde hace tiempo se han mostrado difíciles para las máquinas. En particular, el Deep Learning ha logrado los siguientes avances, todos ellos en áreas históricamente difíciles del Machine Learning.
- Un nivel casi humano para la clasificación de imágenes.
- Un nivel casi humano para el reconocimiento del lenguaje hablado.
- Un nivel casi humano en el reconocimiento de escritura.
- Grandes mejoras en traducciones de lenguas.
- Grandes mejoras en conversaciones text-to-speech.
- Asistentes digitales como Google Now o Siri.
- Un nivel casi humano en autos autónomos.
- Mejores resultados de búsqueda en la web.
- Grandes mejoras para responder preguntas en lenguaje natural.
- Alcanzado Nivel maestro (superior al humano) en varios juegos.
En muchos sentidos, el Deep Learning todavía sigue siendo un campo misterioso para explorar, por lo que seguramente veremos nuevos avances en nuevas áreas utilizando estas técnicas. Tal vez algún día el Deep Learning ayuda a los seres humanos a hacer ciencia, desarrollar software y mucho más.
¿Por qué estos sorprendentes resultados surgen ahora?
Muchos de los conceptos del Deep Learning se desarrollaron en los años 80s y 90s, algunos incluso mucho antes. Sin embargo, los primeros resultados exitosos del Deep Learning surgieron en los últimos 5 años. ¿qué fue lo que cambio para lograr la popularidad y éxito de los modelos basados en Deep Learning en estos últimos años?
Si bien existen múltiples factores para explicar esta revolución del Deep Learning, los dos principales componentes parecen ser la disponibilidad de masivos volúmenes de datos, lo que actualmente se conoce bajo el nombre de Big Data; y el progreso en el poder de computo, especialmente gracias a los GPUs. Entonces, dentro de los factores que explican esta popularidad de los modelos de Deep Learning podemos encontrar:
-
La disponibilidad de conjuntos de datos enormes y de buena calidad. Gracias a la revolución digital en que nos encontramos, podemos generar conjuntos de datos enormes con los cuales alimentar a los algoritmos de Deep Learning, los cuales necesitan de muchos datos para poder generalizar.
-
Computación paralela masiva con GPUs. En líneas generales, los modelos de redes neuronales no son más que complicados cálculos numéricos que se realizan en paralelo. Gracias al desarrollo de los GPUs estos cálculos ahora se pueden realizar en forma mucho más rápida, permitiendo que podamos entrenar modelos más profundos y grandes.
-
Funciones de activación amigables para Backpropagation. La progación hacia atrás o Backpropagation es el algoritmo fundamental que hace funcionar a las redes neuronales; pero la forma en que trabaja implica cálculos realmente complicados. La transición desde funciones de activación como
tanhosigmoida funciones como ReLU o SELU han simplificado estos problemas. -
Nuevas arquitecturas. Arquitecturas como Resnets, inception y GAN mantienen el campo actualizado y continúan aumentando las flexibilidad de los modelos.
-
Nuevas técnicas de regularización. Técnicas como dropout, batch normalization y data-augmentation nos permiten entrenar redes más grandes con menos peligro de sobreajuste.
-
Optimizadores más robustos. La optimización es fundamental para el funcionamiento de las redes neuronales. Mejoras sobre el tradicional procedimiento de SGD, como ADAM han ayudado a mejorar el rendimiento de los modelos.
-
Plataformas de software. Herramientas como TensorFlow, Theano, Keras, CNTK, PyTorch, Chainer, y mxnet nos permiten crear prototipos en forma más rápida y trabajar con GPUs sin tantas complicaciones. Nos permiten enfocarnos en la estructura del modelo sin tener que preocuparnos por los detalles de más bajo nivel.
Otra razón por la que el Deep Learning ha tenido tanta repercusión últimamente además de ofrecer un mejor rendimiento en muchos problemas; es que el Deep Learning esta haciendo la resolución de problemas mucho más fácil, ya que automatiza completamente lo que solía ser uno de los pasos más difíciles y cruciales en el flujo de trabajo de Machine Learning: la ingeniería de atributos. Antes del Deep Learning, para poder entrenar un modelo, primero debíamos refinar las entradas para adaptarlas al tipo de transformación del modelo; teníamos que cuidadosamente seleccionar los atributos más representativos y desechar los poco informativos. El Deep Learning, en cambio, automatiza este proceso; aprendemos todos los atributos de una sola pasada y el mismo modelo se encarga de adaptarse y quedarse con lo más representativo.
¿Cómo mantenerse actualizado en el campo de Deep Learning?
El campo del Deep Learning se mueve muy rápidamente, con varios papers que se publican por mes; por tal motivo, mantenerse actualizado con las últimas tendencias del campo puede ser bastante complicado. Algunos consejos pueden ser:
-
Estarse atento a las publicaciones en arxiv, especialmente a la sección de machine learning. La mayoría de los papers más relevantes, los vamos a poder encontrar en esa plataforma.
-
Seguir el blog de keras en el cual podemos encontrar como implementar varios modelos utilizando esta genial librería.
-
Seguir el blog de openai en dónde detallan las investigaciones que van realizando, especialmente trabajando con GANs.
-
Seguir el blog de Google research; en dónde se viene haciendo bastante foco en los modelos de Deep Learning.
-
Utilizar la sección de Machine Learning de reddit.
-
Suscribirse al podcast Talking machines; en dónde se entrevista a los principales exponentes del campo de la Inteligencia Artificial.
-
Por último, obviamente estar atentos a las publicaciones que se realizan en IAAR.